One of our customer service’s (CS) requirement was to be able to retrieve from M3 a combined .pdf file containing the 3 main documents they usually send to the forwarding agent :
- CMR (MWS610PF) : used for customs, international shipments
- Customer invoice (OIS199PF)
- Packing list (MMS480PF)
This requirement is not possible to meet in standard, even with Infor Document Management (IDM) installed within our M3 environment.
At the time being, CS team must :
- retrieve one by one each correct .pdf file (we have duplicates on CMR… to solve)
- print each document
- scan the batch of files and send it to their personal mailbox
- forward it to the proper “mail to”
The idea here is to offer the possibility to the final user to easily trigger “on demand” the combined .pdf files for one delivery index and receive it automatically in their mailbox.
This post is a starting point and present what can be done. The process can certainly be enhanced, so feel free to comment.
Technical choice made :
- create a widget in Smart Office : allow document selection and delivery number entry
- check data entered, return error if needed
- trigger a MEC mapping that will fetch the requested files through a XQuery in IDM database (that’s where the IDM API play a role) + merge the files + send the result by email with attachment
note : MEC has been used because i actually don’t know well how to use an assembly in .NET but i am sure we can build a java program and call it directly from the script.
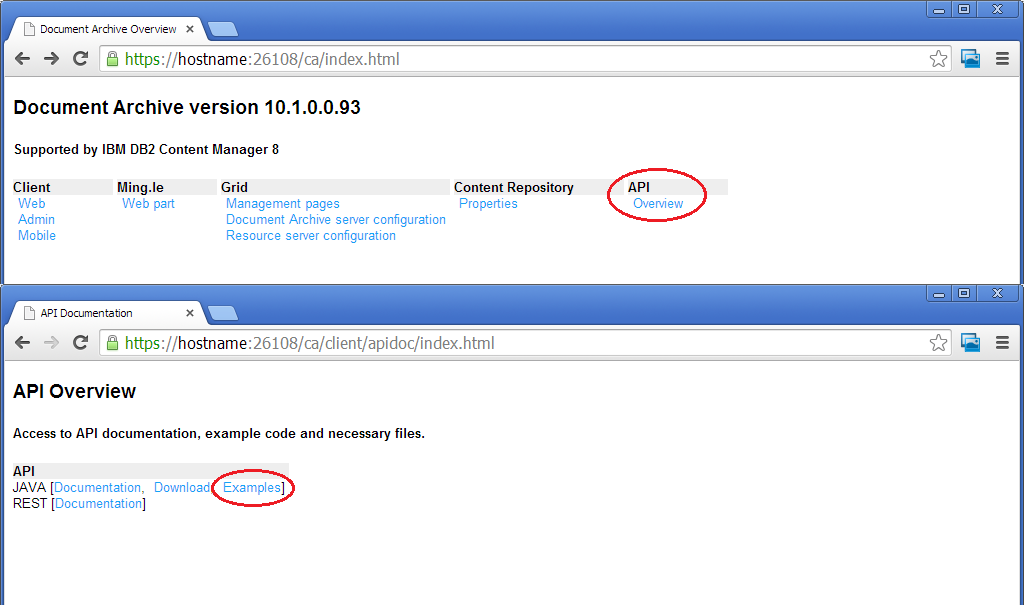
IDM – Infor Document Managment
In IDM, you can XQuery the database, asking for different documents tied to a given delivery number for example, but you can only select one line at a time. And there is no merge possibility at the time being.

Infor provides useful java APIs for IDM, already discussed in Thibaud’s post https://m3ideas.org/tag/document-archive/
The useful one is icp.jar that you can decompile :

The widget
Inspired by another post from Thibaud (https://m3ideas.org/2012/05/08/stand-alone-scripts-for-smart-office/), we create a shortcut on the canvas that will launch the script behind.


The code is pretty straightforward :
var task = new Task(new Uri('jscript://'));
task.AllowAsShortcut = false;
task.VisibleName = 'PDF Merger';
var runner =DashboardTaskService.Current.LaunchTask(task,HostType.Widget);
runner.Status = RunnerStatus.Running;
var host = runner.Host;
host.HostContent = CreateWindow();
host.HostTitle = 'PDF Merger';
host.ResizeMode = ResizeMode.NoResize;
host.Show();
host.Width = 370;
host.Height = 400;
The CreateWindow() function contains a WrapPanel with buttons, labels, textbox and a StatusBar to show some message if needed (it helped me debug).
The GO button has OnClick event.
//Button GO var butGO= new Button(); butGO.Margin = new Thickness(10, 0, 10, 0); butGO.Content = "GO !"; butGO.Width = "40"; butGO.Background = new SolidColorBrush(Colors.Blue); butGO.Foreground = new SolidColorBrush(Colors.White); wrapPanel.Children.Add(butGO); butGO.add_Click(OnClickbutGO);
We monitor at least that :
– the delivery number exist in the system (MIWorker MWS410MI/GetHead)
– the email address of the user exist in CRS111 type 04 (MIWorker CRS111MI/Get)
– the user has selected at least one document (check property IsChecked on checkboxes)
public function OnClickbutGO(sender: Object, e: RoutedEventArgs)
{
if(cb1.IsChecked == false && cb2.IsChecked == false && cb3.IsChecked == false)
{
ConfirmDialog.ShowErrorDialogWithoutCancel("Select at least one document.");
}
else if(EMAIL == '')
{
ConfirmDialog.ShowErrorDialogWithoutCancel("Email address missing in M3.","Check CRS111 type 04 and relaunch the widget.");
}
else if(dlixBox.Text != '')
{
//check DLIX value
try
{
var record = new MIRecord();
record["CONO"] = wCONO;
record["DLIX"] = dlixBox.Text;
MIWorker.Run("MWS410MI", "GetHead", record, OnRunCompletedMWS410MI);
}
catch (ex)
{
debug.WriteLine("ex : "+ex);
}
}
else
{
ConfirmDialog.ShowErrorDialogWithoutCancel("DLIX number is mandatory.");
}
dlixBox.Focus();
}
… and if everything is OK then we trigger the MEC mapping by dropping an XML file into the proper directory.
The XML file is built by using the XmlWriter (System.Xml).
I chose a classic MBM initiator detection in MEC (MBM_S2_R1) and built the global MBM intiator.
This kind of file can be dropped into the input directory. It’s also possible to go for a channel detection where you can drop a more light xml file with the minimum of tags; in this case, you can drop all the tags used for detection by the partner administrator.
Minimum mandatory data to transfer to MEC is :
- the XQuery : tag “DocumentVariant”
- the email address of the user (extracted from CRS111MI) : tag “DocumentNumber”
You can change the tags at your convenience!
function buildXMLTrigger()
{
var request : String = "(";
if(cb1.IsChecked == true) request = request + "/CMR|";
if(cb2.IsChecked == true) request = request + "/CustomerInvoice|";
if(cb3.IsChecked == true) request = request + "/DeliveryNote|";
request = request + ")";
statusbar.AddMessage(EMAIL);
try
{
var xmlWriter = XmlWriter.Create("\\"+"\\YourServer\\PDF_Merger\\trigger"+dlixBox.Text+".xml");
//MvxEnvelope
xmlWriter.WriteStartDocument();
xmlWriter.WriteStartElement("MvxEnvelope");
//SubmitterID
xmlWriter.WriteStartElement("SubmitterID");
xmlWriter.WriteStartElement("Host");
xmlWriter.WriteString("GGM3");
xmlWriter.WriteEndElement();
xmlWriter.WriteStartElement("EnvironmentID");
xmlWriter.WriteString("M3FDBPRD");
xmlWriter.WriteEndElement();
xmlWriter.WriteStartElement("Program");
xmlWriter.WriteString("PDF_MERGER");
xmlWriter.WriteEndElement();
xmlWriter.WriteEndElement();//SubmitterID
//Target
xmlWriter.WriteStartElement("Target");
//e-collaborator
xmlWriter.WriteStartElement("e-collaborator");
//Sender
xmlWriter.WriteStartElement("Sender");
//Reference1
xmlWriter.WriteStartElement("Reference1");
//Data
xmlWriter.WriteStartElement("Data");
xmlWriter.WriteString(UserContext.CurrentCompany);
xmlWriter.WriteEndElement();//Data
xmlWriter.WriteEndElement();//Reference1
//Reference2
xmlWriter.WriteStartElement("Reference2");
//Data
xmlWriter.WriteStartElement("Data");
xmlWriter.WriteString(UserContext.CurrentDivision);
xmlWriter.WriteEndElement();//Data
xmlWriter.WriteEndElement();//Reference2
xmlWriter.WriteEndElement();//Sender
//Recipients
xmlWriter.WriteStartElement("Recipients");
//Recipient
xmlWriter.WriteStartElement("Recipient");
//Reference1
xmlWriter.WriteStartElement("Reference1");
//Data
xmlWriter.WriteStartElement("Data");
xmlWriter.WriteString("PDF_MERGER");
xmlWriter.WriteEndElement();//Data
xmlWriter.WriteEndElement();//Reference1
xmlWriter.WriteEndElement();//Recipient
xmlWriter.WriteEndElement();//Recipients
xmlWriter.WriteEndElement();//e-collaborator
xmlWriter.WriteEndElement();//Target
//MvxBody
xmlWriter.WriteStartElement("MvxBody");
//MovexBusinessMessageInitiator
xmlWriter.WriteStartElement("MovexBusinessMessageInitiator");
xmlWriter.WriteStartElement("DocumentNumber");
xmlWriter.WriteString(EMAIL);
xmlWriter.WriteEndElement();
xmlWriter.WriteStartElement("DocumentVariant");
xmlWriter.WriteString(request+"[@M3_DLIX="+dlixBox.Text+"]");
xmlWriter.WriteEndElement();
//MessageKeys
xmlWriter.WriteStartElement("MessageKeys");
//CONO
xmlWriter.WriteStartElement("MessageKey1");
xmlWriter.WriteStartElement("Field");
xmlWriter.WriteString("CONO");
xmlWriter.WriteEndElement();
xmlWriter.WriteStartElement("Value");
xmlWriter.WriteString(UserContext.CurrentCompany);
xmlWriter.WriteEndElement();
xmlWriter.WriteEndElement();
//DIVI
xmlWriter.WriteStartElement("MessageKey2");
xmlWriter.WriteStartElement("Name");
xmlWriter.WriteString("DIVI");
xmlWriter.WriteEndElement();
xmlWriter.WriteStartElement("Value");
xmlWriter.WriteString(UserContext.CurrentDivision);
xmlWriter.WriteEndElement();
xmlWriter.WriteEndElement();
//DLIX
xmlWriter.WriteStartElement("MessageKey3");
xmlWriter.WriteStartElement("Name");
xmlWriter.WriteString("DLIX");
xmlWriter.WriteEndElement();
xmlWriter.WriteStartElement("Value");
xmlWriter.WriteString(dlixBox.Text);
xmlWriter.WriteEndElement();
xmlWriter.WriteEndElement();
xmlWriter.WriteEndElement();
xmlWriter.WriteEndElement();//MovexBusinessMessageInitiator
xmlWriter.WriteEndElement();//MvxBody
xmlWriter.WriteEndDocument();//MvxEnvelope
xmlWriter.Close();
}
catch(ex)
{
statusbar.AddMessage(ex);
}
}
MEC mapping
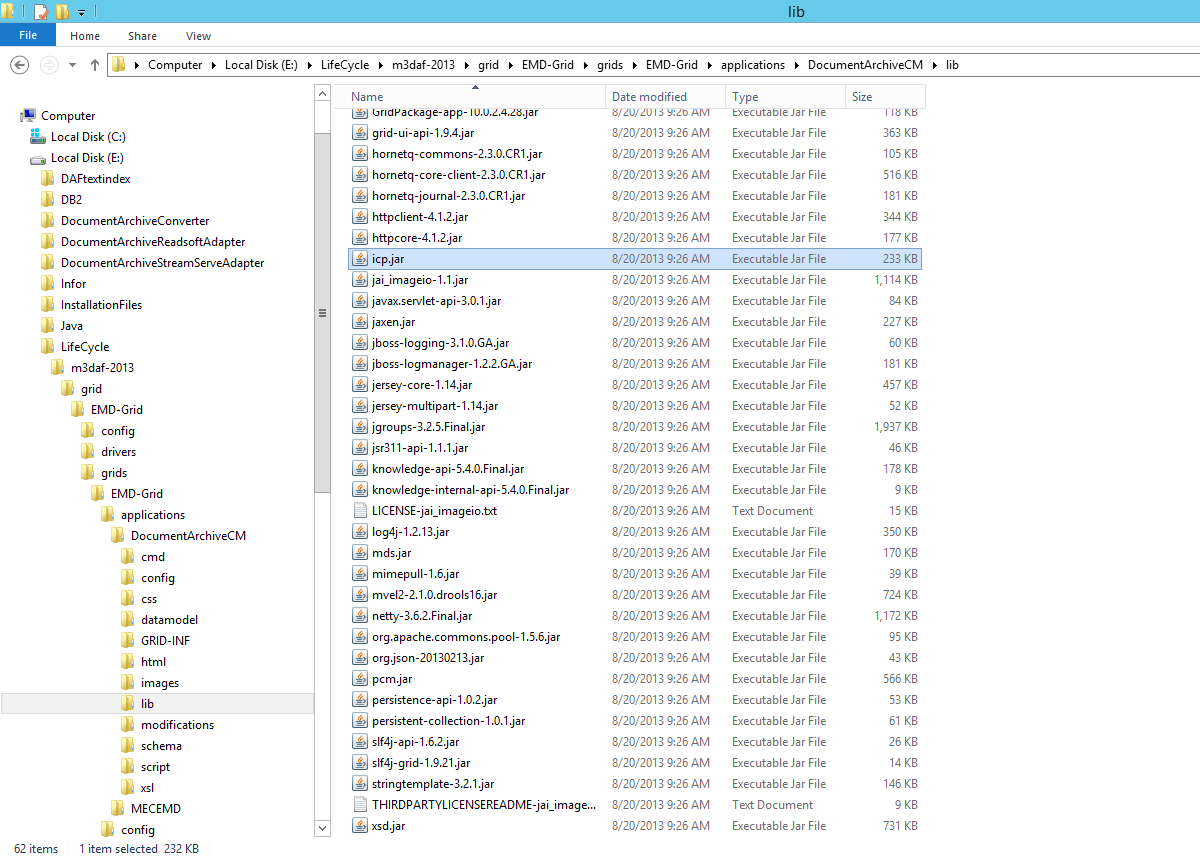
Some .jar are required to read the IDM database and to merge the .pdf files. We already have icp.jar at our disposal.
A quick search on a famous search engine and we find the wonderful and free (!) pdfbox-app-2.0.2.jar that will do the job for us.
https://pdfbox.apache.org/download.cgi
In the ION mapper, import those .jar to the library :

The mapping is reduced the following one :

- one function to retrieve the urls of all the .pdf files based on the user’s document selection + build the report in HTML
try
{
// Create and connect the connection
com.infor.daf.icp.Connection conn = new com.infor.daf.icp.Connection("https://yourServer:20108/ca/", "login", "password", com.infor.daf.icp.Connection.AuthenticationMode.BASIC);
conn.connect();
String FlagFirst = "1";
String docType = "";
org.apache.pdfbox.multipdf.PDFMergerUtility ut = new org.apache.pdfbox.multipdf.PDFMergerUtility();
// Execute an XQuery search and print the display name for all items
com.infor.daf.icp.CMItems items = com.infor.daf.icp.CMItems.search(conn, DocumentVariant, 0, 100);
for(com.infor.daf.icp.CMItem item : items)
{
for(com.infor.daf.icp.CMResource res : item.getResources().values())
{
if(res.getMimeType().equals("application/pdf"))
{
if(FlagFirst.equals("1"))
{
String InitHTML = "<h1>PDF Merger report</h1><TABLE COLS=\"3\" FRAME=\"ALL\" BORDER-COLOR=\"Black\" BORDER=\"1\" VALIGN TD=\"MIDDLE\">";
String Titles = "<tr><th BGCOLOR=\"Navy\"><font COLOR=\"WHITE\">Doc type</font></th><th BGCOLOR=\"Navy\" <font COLOR=\"WHITE\">Doc name</font></th><th BGCOLOR=\"Navy\" <font COLOR=\"WHITE\">Version</font></th></tr>";
TEXT = InitHTML + Titles;
FlagFirst = "0";
}
if(res.getFilename().contains("MMS480PF")) docType = "Packing list";
if(res.getFilename().contains("MWS610PF")) docType = "CMR";
if(res.getFilename().contains("OIS199PF")) docType = "Cust. invoice";
TEXT = TEXT + "<tr><td ALIGN =\"MIDDLE\">"+docType+"</td><td ALIGN =\"MIDDLE\">" +res.getFilename()+ "</td><td ALIGN =\"MIDDLE\">"+item.getVersion()+"</td></tr>";
ut.addSource(res.getUrlStream());
}
}
System.out.println("\n NodeName : " + item.getNodeName());
}
if(FlagFirst.equals("0"))
{
TEXT = TEXT + "</TABLE>";
}
ut.setDestinationFileName(getManifestInfo("agr:pathFrom")+"Docs_"+iValue+".pdf");
fileAttachment = getManifestInfo("agr:pathFrom")+"Docs_"+iValue+".pdf";
ut.mergeDocuments();
conn.disconnect();
}
catch(Exception e)
{
e.printStackTrace();
}
EMAIL = DocumentNumber;
DLIX = iValue;
- one function to send an email with attachment
try
{
// SMTP
java.util.Properties props = new java.util.Properties();
props.put("mail.smtp.host", constMailServer);
// session
javax.mail.Session session = javax.mail.Session.getDefaultInstance(props, null);
javax.mail.internet.InternetAddress addressFrom = new javax.mail.internet.InternetAddress(constFrom);
// Create msg
javax.mail.Message msg = new javax.mail.internet.MimeMessage(session);
msg.setFrom(addressFrom);
javax.mail.internet.InternetAddress addressTo[] = javax.mail.internet.InternetAddress.parse(EMAIL);
msg.setRecipients(javax.mail.Message.RecipientType.TO, addressTo);
msg.setSubject("PDF MERGED documents for delivery "+DLIX);
javax.mail.internet.MimeBodyPart messageBodyPart = new javax.mail.internet.MimeBodyPart();
messageBodyPart.setContent(TEXT,"text/html");
javax.mail.Multipart multipart = new javax.mail.internet.MimeMultipart();
multipart.addBodyPart(messageBodyPart);
messageBodyPart = new javax.mail.internet.MimeBodyPart();
javax.activation.DataSource source = new javax.activation.FileDataSource(fileAttachment);
messageBodyPart.setDataHandler(new javax.activation.DataHandler(source));
messageBodyPart.setFileName("Documents_"+DLIX+".pdf");
multipart.addBodyPart(messageBodyPart);
msg.setContent(multipart);
javax.mail.Transport.send(msg);
}
catch(javax.mail.MessagingException e)
{
throw new MeCError(e.getMessage());
}
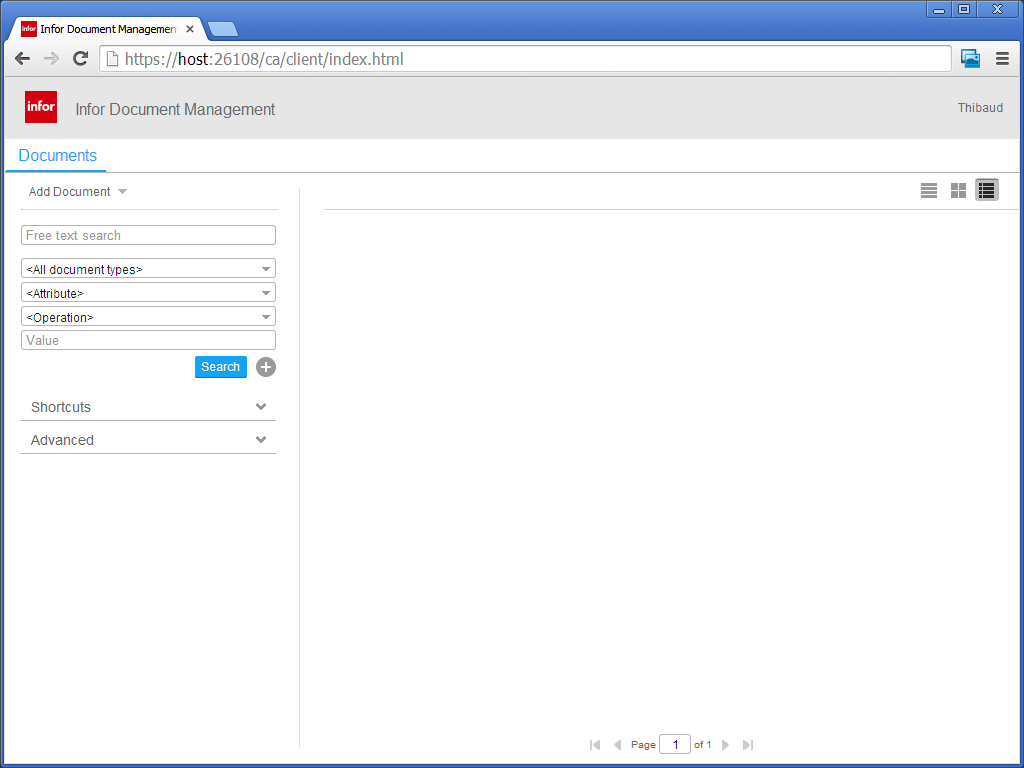
Last but not the least, the final result in a screenshot :

The attachment’s name contains the delivery number and the report displays all the .pdf retrieved from IDM.
Note : there are 3 invoices in the delivery (according to customer settings), 1 packing list and 1 CMR (with a duplicate…)
That’s it! Happy coding !
Maxime.