HI, I am Walter. This is my first post in this blog which was usefull just more than once for me in past … now I want to contribute something also from my side…
In past I have done a lot of data exports and imports via M3API over VBA in Excel. This works fine too, but this has 2 problems:
- you have to pay attention if you share the files (security)
- there are no good practicable solution for automation of the scripts
In past I have done a lot of work also with data integration tools, one of the most used is Pentaho Spoon (PDI). So I startet some investigation of how to integrate M3 API with PDI. This is a short how to call M3 API using the data integration tool Pentaho Spoon (ex. Kettle), also known as Pentaho PDI.
Data integration tools are usefull for extracting, manipulating and writing data from and to different in and outputs.

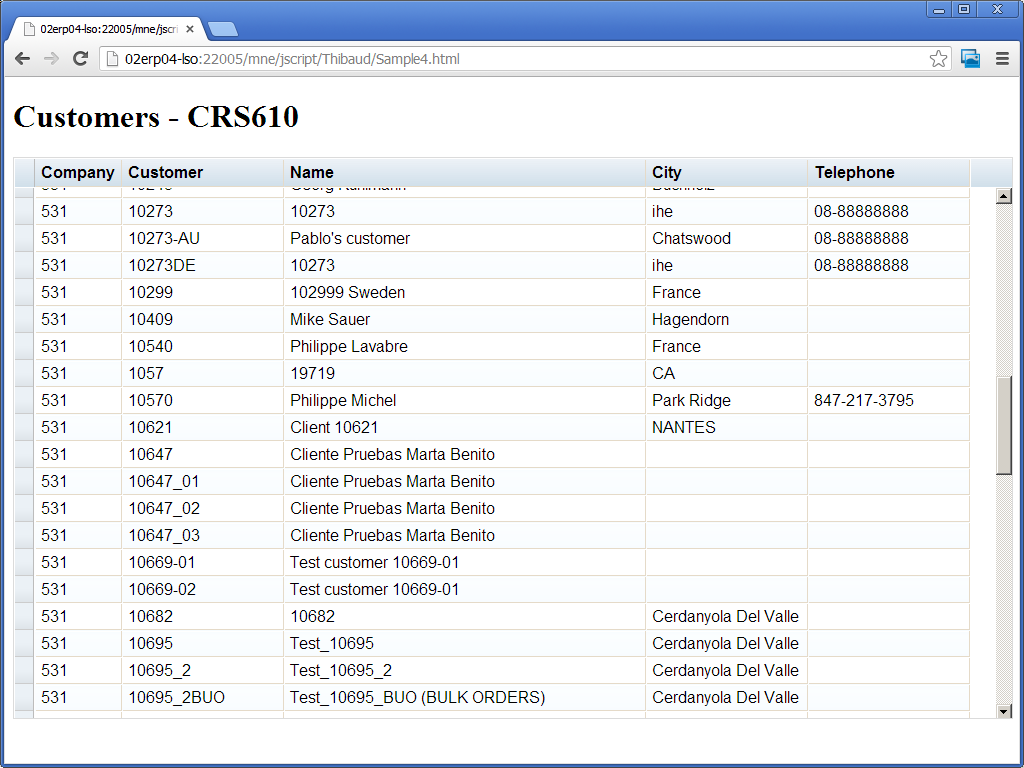
In this example I use Kettle to extract Customerdata, transform it and save it in a csv file.
Pentaho Spoon is a very powerful tool, is based on a opensource licence and the community edition can be downloaded here. The package is platform independent and the transformation files can be build in Windows, and used on a Linux environemnt or viceversa. Probably only some path variables must be changed.
Preparation
This example is based on windows environment, but the same can be done without any problems also on Linux environment.
- Download the Pentaho PDI package from the link above. Unzip the package and copy/paste the folder where every you want. For example directly under C:\
- You need a newer version of API Toolkit where also java library is available. All you need for this example is the library MvxAPI.jar which normally is located in the MvxAPI Folder.
- Copy the MvxAPI.jar lib to the lib Folder of Pentaho PDI, normally located in the data-integration folder.
- Start Pentaho PDI
Lets start
The target is to read data from M3 via the M3 API. For this purpose we use the Java library. Pentaho PDI uses graphical transformation steps which help you to create a data transformation. For some of this steps it needs also little bit of programming knowledge. But don’t worry, there are many examples in the MvxAPI package about calling M3 API via Java. And also for Pentaho PDI there are many examples for each transformation step.
For calling M3 API via PDI we use the transformation step “User Defined Java Class” (UDJC)
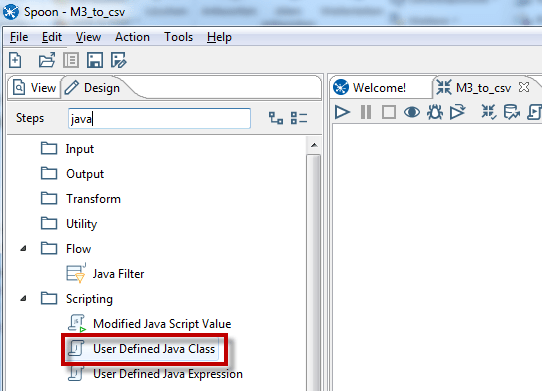
In total for this example I have used 6 different transformation steps:
- Get Variables – call variables from kettle.properties file located under your home/.kettle directory

- User defined Java Class – Call API and forward all retrieved records to next step.
- Strings cut – split the API stream in individual fields.
- Select values – filtering of columns which should be forwarded to next step.
- Trim – trim the blanks before and after the column values.
- Text file output – write the selected and cleaned values in a csv file.
It looks like this now:
As just explained you need to make some java development in the UDJC (User defined java class) step. Here is my piece of cake:
import java.util.regex.Pattern;
import java.util.*;
import MvxAPI.*;
private Pattern p = null;
private FieldHelper fieldToTest = null;
private FieldHelper outputField = null;
private ArrayList keys = null;
private int idx = 0;
MvxSockJ obj2;
int i, j, x;
String str,str2;
String sendstr;
double ver;
String test, MvxERR;
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException
{
//Initialize rows
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
//assign system variables from previous step (kettle.properties)
String M3_System = get(Fields.In, “M3_System”).getString(r);
int M3_Port = get(Fields.In, “M3_Port”).getInteger(r).intValue();
String M3_User = get(Fields.In, “M3_User”).getString(r);
String M3_Pass = get(Fields.In, “M3_Pass”).getString(r);
//Create new row output
r = createOutputRow(r, data.outputRowMeta.size());
/**
* Setup communication parameters for M3
*/
//open the connection with system variables forwarded from previous step
obj2=new MvxSockJ(M3_System, M3_Port, “”, 0, “”);
obj2.DEBUG = true; // Have MvxSockJ print out debug info
//Call the MI with user and pass forwarded from previous step
i = obj2.mvxInit(“”, M3_User, M3_Pass, “CRS610MI”);
if(i>0) {
get(Fields.Out, “error”).setValue(r, “Error: ” +obj2.mvxGetLastError());
putRow(data.outputRowMeta, r);
return true;
}
ver=obj2.mvxVersion();
get(Fields.Out, “version”).setValue(r, ver);
/**
* Build the transaction
*/
sendstr = “LstByNumber 1 “;
//Set max records
str=obj2.mvxTrans(“SetLstMaxRec 50 “);
//Run the transaction
str=obj2.mvxTrans(sendstr);
if(str.startsWith(“NOK”)) {
get(Fields.Out, “error”).setValue(r, “Error:” +str);
}
x=0;
if(str != null) {
while (str.startsWith(“REP”)) {
x=x+1;
/**
* This prints out the whole returned string without trying to
* extract particular fields from the layout.
*/
// Set key and value in a new output row
get(Fields.Out, “crs610_stream”).setValue(r, str);
get(Fields.Out, “idx”).setValue(r, x);
// Send the row to the next step.
putRow(data.outputRowMeta, r);
str=obj2.mvxRecv();
}
}
else
get(Fields.Out, “error”).setValue(r, “Error: ” +obj2.mvxGetLastError());
putRow(data.outputRowMeta, r);
i=obj2.mvxClose(); // close connection
return true;
}
The class is calling the CRS610MI and reads the first 50 records. This records are forwarded then to the next step.
At the end the of the transformation the output is saved in the file C:\TEMP\crs610.csv
The whole transformation with all contained steps will be saved in a file with .ktr extension. Here you can download the example file! You have to accept the self signed certificate. Don’t worry, there is no risk 😉
Conclusion
After a short time of investigation I was able to build a really performant transformation. For reading, transforming and writing up to 10.000 records the transformation it needs less the 30 seconds. In my eyes a good performance.
Clearly you can do all what do you want with the data, save in another database, combine the data with additional datasources, save in Excel or send to another server via REST, SOAP, JSON webservice, or whatever is your requirement.
If you are not familiar with Pentaho PDI (Spoon) there are many How to’s in the web, in the Examples folder are many examples which gives you an idea how to work with PDI.
And for me the most important function that the transformation can be scheduled in combination with “Kittchen”, which is also part of Pentaho PDI.
Next steps
My next target is to write data via API in M3 using PDI. I will keep you updated about it. Hope this is may usefull for somebody of you! Let me know.. if you have any questions let me know.
Thank you,
Walter