For my project to get M3 picking lists in Google Glass, I had to learn how to retrieve in Java an image that is stored in Infor Document Archive. The technique is probably well explained and documented somewhere, but I don’t work with Document Archive so I didn’t know where to start. So as a starting point, I used one of the Java examples built-in Document Archive 10.1.x, and from there I adapted the code for the older Document Archive 10.0.x. I share my results here with you in case you too need to retrieve resources in Java from Document Archive and don’t know where to start. I will later use that code in my Infor Grid application to insert the picture of the item in the picking list in Glass.
Built-in examples
Document Archive 10.1.x is built-in with some examples in Java to connect to the server and retrieve resources. I compiled that code and it ran out of the box. I then used it as a basis to adapt the code to the older Document Archive 10.0.x for which I couldn’t find built-in examples. I will show you the code for both versions. I will also show how to encode the bytes to Base64 as I might need it later for the Google Glass Mirror API.
Code for Document Archive 10.1.x
Here is the Java source code for Document Archive 10.1.x:
import java.io.FileOutputStream;
import java.io.InputStream;
import com.infor.daf.icp.CMItem;
import com.infor.daf.icp.CMResource;
import com.infor.daf.icp.Connection;
import com.infor.daf.icp.SearchQueries;
import com.infor.daf.icp.SearchQuery;
import com.infor.daf.icp.Connection.AuthenticationMode;
import org.apache.commons.codec.binary.Base64;
public class Test {
public static void main(String[] args) {
try {
String baseUrl = "https://hostname:26108/ca/";
String username = "JOHNDOE";
String password = "*******";
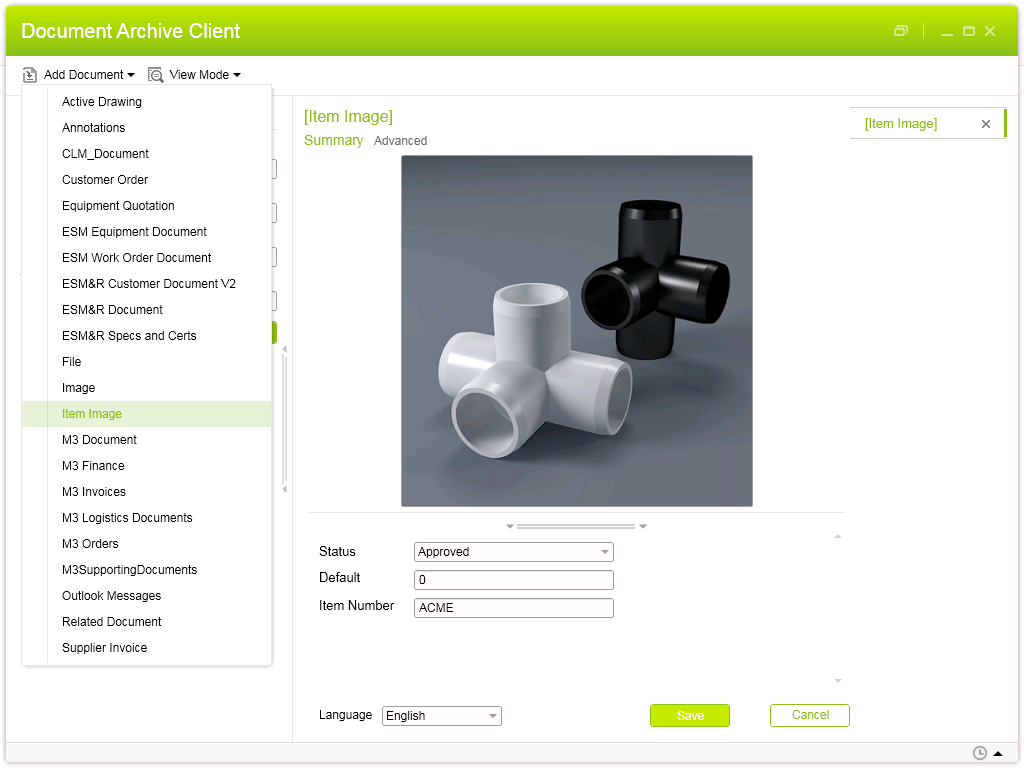
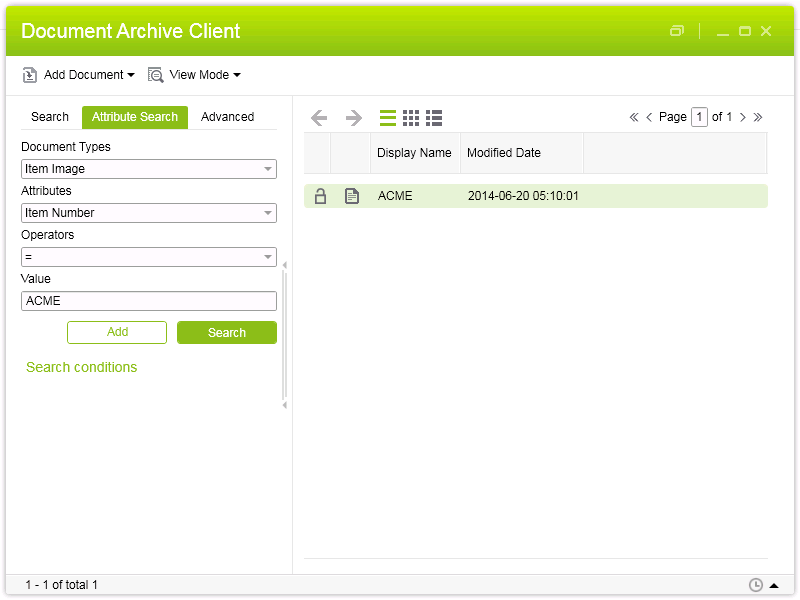
String query = "/M3_ITEM_IMAGE[@M3_ITNO = \"ACME\"]";
Connection conn = new Connection(baseUrl, username, password, AuthenticationMode.BASIC);
conn.connect();
CMItem item = CMItem.search(conn, new SearchQueries(new SearchQuery(query)));
for(CMResource res : item.getResources().values()) {
// to file
FileOutputStream fos = new FileOutputStream(res.getFilename());
InputStream is = res.getUrlStream();
CMResource.streamData(is, fos, true);
// to URL
System.out.println(res.getUrl().toString());
// to Base64
byte[] bytes = CMResource.createByteArray(res.getUrlStream());
System.out.println(new String(Base64.encodeBase64(bytes)));
}
conn.disconnect();
} catch(Exception e) {
e.printStackTrace();
}
}
}
Find the Java library for Document Archive 10.1.x, icp.jar, and the required open source libraries httpclient, httpcore, commons-logging, commons-codec, and jaxen:
<LifeCycle>\<host>\grid\<grid>\grids\<grid>\applications\DocumentArchiveCM\lib\

Compile and run the code with:
javac -extdirs . Test.java
java -cp icp.jar;httpclient-4.3.2.jar;httpcore-4.3.1.jar;commons-logging-1.1.1.jar;commons-codec-1.6.jar;jaxen.jar;. Test
The application will connect to Document Archive, will search the image by query, will retrieve the resource and will save it to a file, for example to JPEG.
The application will also show the URL to the resource, for example:
The application will also show the Base64-encoded bytes of the resource.
Code for Document Archive 10.0.x
Here is the Java source code for the older Document Archive 10.0.x. It is very similar to the newer code above, the package names are different (intentia instead of infor) and some methods are older. I had to decompile icp.jar to learn and adapt the code.
import java.io.FileOutputStream;
import java.io.InputStream;
import java.util.Iterator;
import org.apache.commons.codec.binary.Base64;
import com.intentia.icp.common.CMItem;
import com.intentia.icp.common.CMResource;
import com.intentia.icp.common.Connection;
public class Test {
public static void main(String[] args) {
try {
String baseUrl = "https://hostname:25194/ca/";
String username = "JOHNDOE";
String password = "*******";
String query = "/ESA_ItemImage[@ESA_ItemNumber = \"ACME\"]";
Connection conn = new Connection(baseUrl, username, password);
conn.setAuthMode(Connection.BASIC);
conn.connect();
CMItem item = CMItem.search(conn, query);
Iterator it = item.getResources().iterator();
while (it.hasNext()) {
CMResource res = (CMResource)it.next();
// to XML
System.out.println(res);
// to file
if (res.getEntityName().equals("ICMBASE")) {
InputStream is = res.retrieveResource(conn);
FileOutputStream fos = new FileOutputStream(res.getOrgFileName());
CMResource.streamData(is, fos);
// to Base64
byte[] bytes = CMResource.createByteArray(res.retrieveResource(conn));
System.out.println(new String(Base64.encodeBase64(bytes)));
}
}
conn.disconnect();
} catch(Exception e) {
e.printStackTrace();
}
}
}
Find the Java library for Document Archive 10.0.x, icp.jar, and the required open source libraries httpclient, httpcore, commons-logging, commons-codec, jaxen, and commons-io:
<LifeCycle>\<host>\grid\<grid>\grids\<grid>\applications\DocumentArchiveCM\lib\
Compile and run the code with:
javac -extdirs . Test.java
java -cp icp.jar;jaxen-1.1.1.jar;httpclient-4.2.2.jar;httpcore-4.2.2.jar;commons-io-2.4.jar;commons-logging-1.1.1.jar;commons-codec-1.7.jar;. Test
The application will connect to Document Archive, will search the image by query, will retrieve the resource and will save it to a file, for example to JPEG.
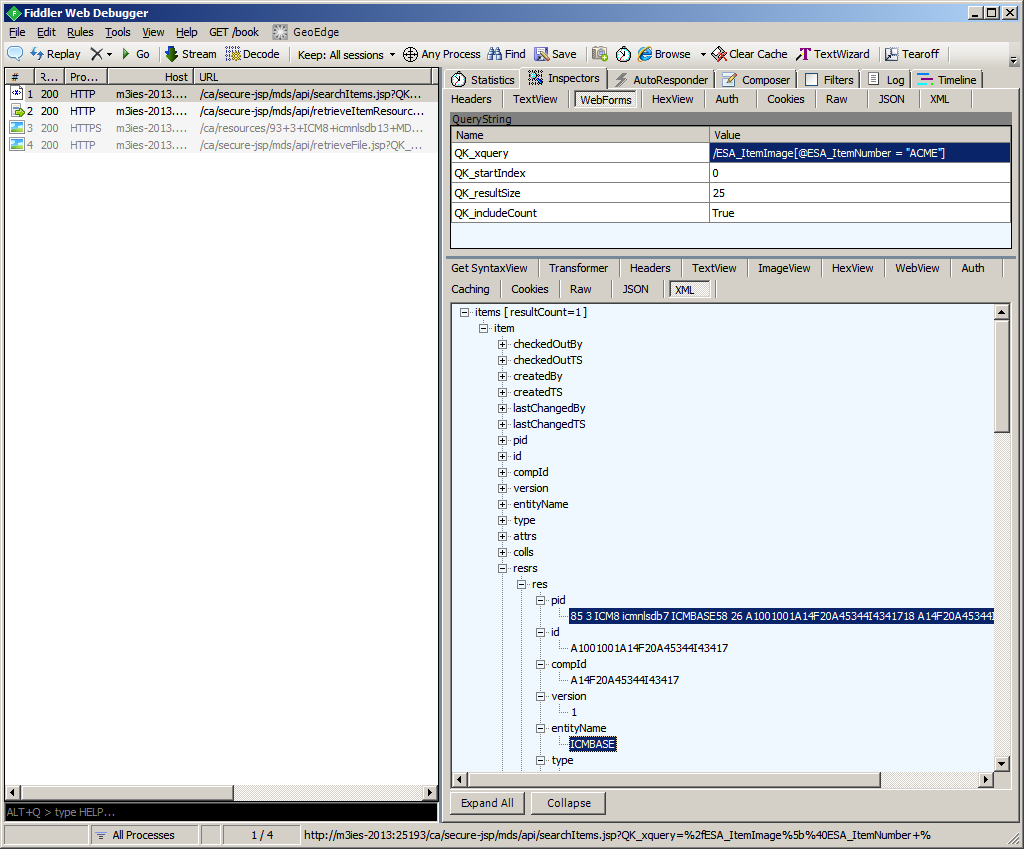
The application will also show the XML of the resource, for example:
<?xml version="1.0" encoding="UTF-16" standalone="no"?>
<res>
<pid>85 3 ICM8 icmnlsdb7 ICMBASE58 26 A1001001A14F20A45344I4341718 A14F20A45344I434171 13 300</pid>
<id>A1001001A14F20A45344I43417</id>
<compId>A14F20A45344I43417</compId>
<version>1</version>
<entityName>ICMBASE</entityName>
<type>0</type>
<acl>
<name>defaultACL</name>
</acl>
</res>
The application will also show the Base64-encoded bytes of the resource.
That’s it. If you liked this, please click Like, leave me your thoughts in the comments below, and share your solutions by writing posts.
Also, please join the campaign and sign the petition to Infor so they make more of their source code available such that we can all learn more and make better solutions.
Thank you.