Today I’ll illustrate two usability ideas for Infor M3 – content-aware re-sizing of M3 programs, and text interpolation – to make M3 more usable on high resolution screens.
Synopsis
The M3 user interface was built over 20 years ago for AS/400 and 5250 screens of 73 up to 98 columns and 23 rows, that’s about 0.0022 Mega-characters. The M3 user interface has evolved over the years and has stabilized in Smart Office around the same number of columns and rows as 20 years ago with each cell measuring 10 x 22 pixels at 100% zoom level, that’s about 0.5 Megapixels. It’s about the same for Infor H5 Client.
Meanwhile, screen resolutions and pixel density have continued to increase at an incredible pace. Mobile phones are being produced in China with a horizontal resolution of 3,000 pixels (3K). Televisions are being produced in Japan with a horizontal resolution of 8,000 pixels (8K). And the trend will continue. I even started working on a laptop that has a 3K screen, 3200 x 1800, that’s 5.8 Megapixels or a seven-fold increase in available pixels compared to 1024 x 768. The number of pixels on the surface grows to the square of the linear resolution, for example if we multiply by two the screen resolution on each axis from 1600 x 900 to 3200 x 1800 that’s a four-fold increase in surface.
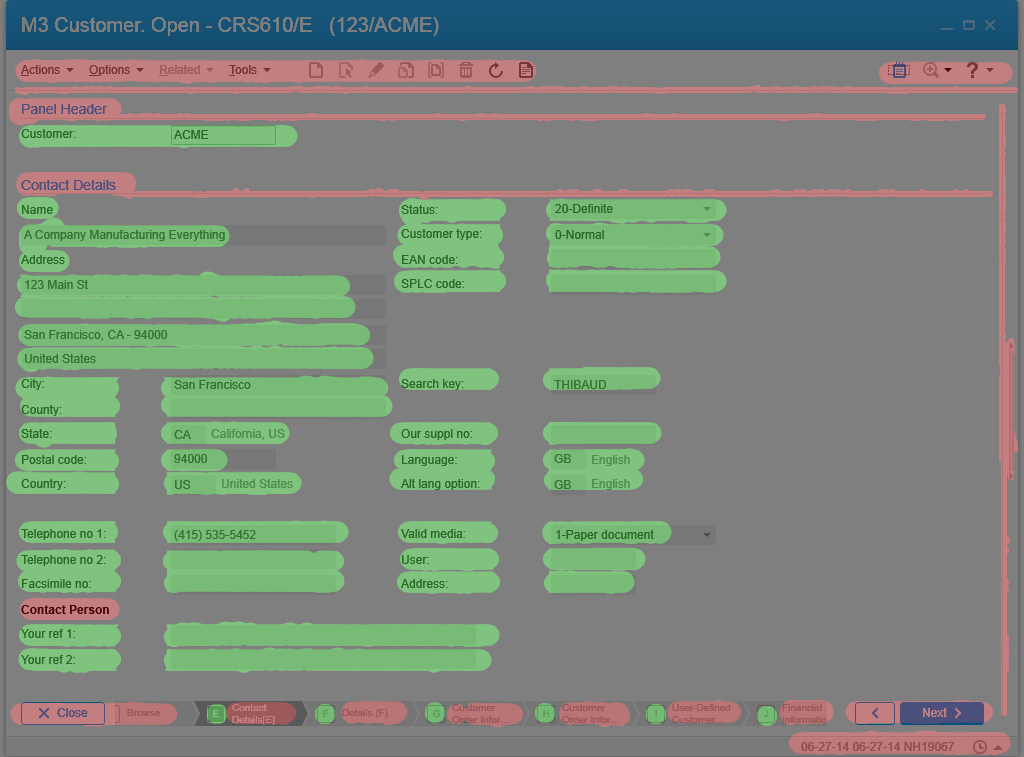
Despite those technological advances, the M3 user interface hasn’t adapted. Here is a screenshot of Smart Office on my laptop with a screen resolution of 3200 x 1800 pixels, showing CRS610/E sized to 1024 x 768 pixels at the top left corner; the result evidently illustrates how the majority of the space is unused:

There are numerous technical challenges to increasing the number of rows and columns of M3 programs, leading to problems in the database and in legacy source code, but there are several steps we can take in that direction.
Two years ago I illustrated the usability idea how to tile windows in Smart Office. Today, I will illustrate two new ideas: content-aware re-sizing of M3 programs, and text interpolation.
Content-aware re-sizing of M3 programs
The first usability idea is to implement content-aware re-sizing of M3 programs with inspiration from seam carving as introduced by Shai Avidan and Ariel Shamir in 2007. You can watch a demonstration of seam carving in the authors video here. The idea of seam carving is to calculate the energy function of neighboring pixels and remove paths of lowest energy in a way that respects the overall composition of the image. We can manipulate the energy values to keep certain pixels and discard others.
To try seam carving, you can use the Content Aware Scaling feature in Adobe Photoshop, or the Liquid Rescale plugin for Gimp, or the online tool RSIZR.
Here is an example of CRS610/E in RSIZR; I used the preserve and remove brushes to mark in green the important portions of CRS610/E to keep and in red the portions to discard:
Previous known techniques to re-size windows include re-scaling but it causes cropping and scrollbar hell, and re-sizing but it causes the image to be squooshed and minimized. The ideal solution is re-targeting with content-aware re-sizing.
Here is a video of the result using a screenshot of CRS610/E in RSIZR:
It’s not possible to simply implement seam carving to M3 because the rendering of the M3 user interface is based on text and not on pixels. Yet, we can approximate an implementation by choosing which parts of the user interface we want to keep and which parts we can discard. We can do this with a hierarchy of importance. And we can do this programmatically. The new M3 user interface does something similar with the adaptable panel sequence ribbon.
Text interpolation
The second usability idea is text interpolation in M3 programs for text like column headers and labels.
M3 is translated in multiple languages by professional translators. You can read more about it in the two blog posts: Translate M3 with Google Translate API, and Write a Mashup in multiple languages.
The language constants are chosen in different widths to fit the varying space of the target medium. The size ids are: 03, 05, 10, 15, AA, C0, C1, C2, CA, and CF.
The text is retrieved at run-time based on the user’s language settings in MNS150.
The Java source code of each M3 program maps the fields and message identifiers. For example CRS610DSP.java:
static final String[] fieldNames={
"X0RCID","PXFKEY","WWCLIN","WWCPOS","WBOPT2","S0SFH","WWCOLN","WWPSEQ","WOPAVR","WOUPVR",
"WWQTTP","WWNFTR","WWAGGR","WXSLCT","WFSLCT","WTSLCT","WXSLC2","WFSLC2","WTSLC2","WXSLC3",
"WFSLC3","WTSLC3","WXTXT1","WXTXT2","WXTXT3","WXTXT4","WXTXT5","WXTXT6","WXTXT7","WXTXT8",
...
"WRGEOC","WRTECN","WRTEEC","WRTAXC","WTTAXC","WRAGBP","WRAGPY","WRACLB","WRAACB","WRAGCP",
"WRAGAC","WRAGPN","WRAGBG","WRAGPG","WRAGTD","OKAGTN","WRAGCA","WTRTEP","WRRPLT","WRRDIS",
"WRRTEP","WRRSMC","WRAOTP","WTRPLT","WTRDIS","WTRSMC","WTAOTP","PXPDSE","WWSPIC","WWDSEQ",
"WWCFEN","WWTPIC","WWTXVR","WWLNCD"};
static final String[] fieldMessageIds={
null,null,null,null,null,null,null,null,null,null,
null,null,null,null,null,null,null,null,null,null,
null,null,null,null,null,null,null,null,null,null,
...
"WGE10","WTE26",null,"WTA39","WDE03","WAGB0","WAG69","WAC95","WAACB","WAG78",
"WAG70","WAG73","WAG77","WAG76",null,"WAG75","WAG72","WDE03","WRPLT","WRDIS",
"WRTEP","WRSMC","WAT90",null,null,"WDE03",null,null,null,null,
null,null,null,null};
For example, here are the identifiers of some common fields in CRS610:
- Customer name – CUNM: WNA01
- Customer number – CUNO: WCU02
- Telephone number 1 – PHNO: WPH01
We can get the values in a Smart Office script with:
function ... {
var list: ArrayList = new ArrayList();
list.Add(new TranslationItem(messageId + width, "MVXCON"));
TranslationService.Current.Translate(list, OnTranslation, "GB");
}
function OnTranslation(items: IEnumerable) {
for (var item: TranslationItem in items) {
if (!String.IsNullOrEmpty(item.Text)) {
if (item.Text != item.Key) {
debug.WriteLine('Translated ' + item.Key + ' to ' + item.Text);
} else {
debug.WriteLine('Key ' + item.Key + ' not found in file ' + item.File);
}
} else {
debug.WriteLine('item.Text is null or empty');
}
}
}
That calls the Net Extension command TRANSLATE.
The result would be for example:
PHNO[WPH0103]=Tl1 PHNO[WPH0105]=Tel 1 PHNO[WPH0110]=Tel no 1 PHNO[WPH0115]=Telephone no 1 PHNO[WPH01AA]=telephone number 1
We can then interpolate the resulting Strings, for example my simple algorithm returns:
Tl1 Tel1 Tel 1 Tel n1 Tel nb1 Tel nb 1 Tele nb 1 Telep nb 1 Teleph nb 1 Telepho nb 1 Telephon nb 1 Telephone nb 1 Telephone nub 1 Telephone numb 1 Telephone numbe 1 Telephone number 1
Here’s the simple algorithm I used for that:
/*
Returns the specified headers interpolated one character at a time, first ocurrence of any different character, from left-to-right.
*/
function interpolate(headers) {
var interpolated = new ArrayList();
var str1;
var str2;
for (var i = 0; i < headers.length - 1; i++) {
str1 = headers[i];
str2 = headers[i + 1];
interpolated.Add(str1);
for (var j = 0; j < (str2.length - 1) && str1 != str2; j++) {
if (j < str1.length) {
if (str1[j] != str2[j]) {
// the character at this position of str2 doesn't exist in str1, add it to str1
str1 = str1.Insert(j, str2[j]);
interpolated.Add(str1);
}
} else {
// we reached the tail of str1, add the tail of str2 to str1
str1 = str1.Insert(j, str2[j]);
interpolated.Add(str1);
}
}
}
interpolated.Add(str2);
return interpolated;
}
It turns out the algorithm is not that simple to implement as not all the language constants in M3 can be automatically interpolated, for example the abbreviation no (letter O) would have to be specially interpolated to number (no letter O).
Here is a resulting video of column header interpolation in CRS610/B; I manually sanitized the interpolated Strings and added the field name in parenthesis:
Summary
In this post I illustrated two usability ideas – content-aware re-sizing of M3 programs, and text interpolation – to benefit from the technological advances in ever higher resolution screens and to improve the M3 user interface. This would be specially ideal for large Mashups.
That’s it! If you liked this post, please click the Follow button to subscribe to this blog, leave your comments in the section below, click Like, and share with your peers.

NOTE: We can also use SQL to find the language constants:
SELECT * FROM MVXJDTA.MVXCONGB
WHERE COMSID LIKE ‘WCU02%’
SELECT * FROM MVXJDTA.MVXCONGB
WHERE COMSG=’Customer’
LikeLike