Here is a technique to give custom, rich, interactive, and user-friendly HTML responses to the users of Infor M3 Enterprise Collaborator (MEC), instead of giving them classic HTML, XML, or email responses.
Scope
MEC is an EAI tool that takes input messages, processes them, and produces output messages. I will only focus on interactive scenarios where the user needs an immediate response from MEC. I will only focus on the HTTP channels of MEC. I will assume we already have a request, and I will only focus on the HTML response. So this is a pretty specific scope of use. Note I have not been to a MEC training so my results by trial and error may not be optimal.
Classic responses
Canned response
By default, the HTTPIn channel of MEC produces this minimalist HTML response, with no piece of identifiable data about what it is referring to, no explanation of what “successfully processed” means – there could actually be a failure behind – it is just a basic acknowledgment of receipt, misspelled:
e-Collaborator HTTP Reply
The request was succesfully processed
e-Collaborate!
Custom XML response
With the HTTPSyncIn + HTTPSyncOut channels we can produce a custom response, typically in XML because MEC is XML-centric. In there, we can put identifiable data, and a detailed explanation. I illustrated this scenario in my previous post HTTP channels in MEC (part 3). But XML is not user-friendly thus not suitable for users.
Email response
Many developers setup their MEC agreements to send responses as emails to their users. However, 1) if a user takes an action that merits an immediate response from MEC, receiving an email disrupts the user context, 2) sending emails worsens mailbox pollution, 3) and most email clients block HTML and JavaScript features, thus thwarting interactivity. I prefer to show an HTML page as the primary confirmation, and optionally the email as the secondary confirmation.
Desired HTML response
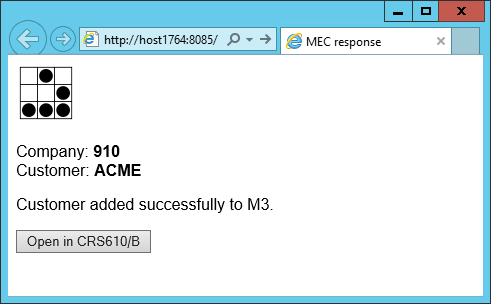
My desired response is dynamic HTML from MEC. To it, I will add images and CSS for beautification, and JavaScript to manipulate the page dynamically. I will reflect the input identifiers onto the output as a feedback loop for the user. I will craft a format that is easy for the user to understand. I will put a detailed message of the processing’s result. And I will add buttons for the user to interact with the result in M3. Here is my example:

Here is my desired dynamic HTML output from MEC. I recommend using HTML5 instead of HTML4 to avoid the quirks:
<!DOCTYPE html>
<html>
<head>
<title>MEC response</title>
<link rel="stylesheet" type="text/css" href="http://host1623:22107/mne/Test.css" />
</head>
<body>
<img src="http://host1623:22107/mne/Test.png" alt="Test" />
Company: <span id="CONO">910</span>
Customer: <span id="CUNO">ACME</span>
Customer added successfully to M3.
<input id="btn" type="button" value="Open in CRS610/B" />
<script type="text/javascript" src="http://host1623:22107/mne/Test.js"></script>
</body>
</html>
Note: for an explanation of that /mne/ path, see the chapter further below about static files.
Here is my static CSS file, Test.css:
body { font-family: sans-serif }
span { font-weight: bold }
Here is my static JavaScript code, Test.js. It opens the customer record in CRS610/B. For that, it uses the Infor Smart Office Installation Point URL, the task parameter [1] and an MForms Bookmark URI [2]:
btn.addEventListener("click", function () {
var CONO = document.getElementById("CONO").innerText;
var CUNO = document.getElementById("CUNO").innerText;
var isoUrl = "http://host1762:22107/mango/MangoClient.application?server=https://host1762:22108";
var bookmarkUri = "mforms://bookmark/?program=CRS610&tablename=OCUSMA&keys=" + encodeURIComponent(["OKCONO", CONO, "OKCUNO", CUNO]);
var url = isoUrl + "&task=" + encodeURIComponent(bookmarkUri);
window.open(url, "_blank");
});
Note 1: You can use anchors <a> instead of buttons if you prefer.
Note 2: You can replace Smart Office by H5 Client if you prefer.
Unsuccessful attempts
I originally tried to produce the HTML output directly from MEC Mapper.
For that, I imported the XHTML 1.0 Strict XML Schema, but MEC Mapper tripped on <xs:import schemaLocation=”…xml.xsd”/>:

I removed it from the XSD and tried again, but then MEC Mapper tripped on <xs:attributeGroup ref>:

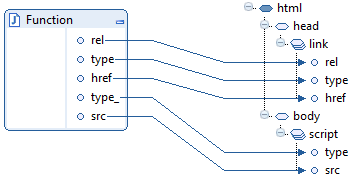
I removed them all from the XSD and tried again, but then MEC Mapper added the document elements as a recursive list of all the possible elements and attributes of HTML, even the ones I did not need and the optional ones, with no flexibility to change:

Instead, I created a minimalist XSD for my sample HTML, but MEC Mapper deleted the values of my attributes, even if I enforced them in the XSD <xs:attribute>:

Then I tried to restore my attribute values with a Java function, but that quickly became un-maintainable for a large HTML document with frequent changes:

And each time I change the XSD, I have to do the cycle of delete/un-publish/save/generate/publish/add/reload/activate [3], and it is too overwhelming for short development cycles.
Too complicated.
FAIL
ABORT
Back to XML
I will revert my mapping back to XML output:
Here is the desired XML output:
<?xml version="1.0"?>
<response>
<CONO>910</CONO>
<CUNO>ACME</CUNO>
<result>OK</result>
</response>
As usual, to create the XSD, I use Microsoft SDK’s xsd.exe, I remove the Byte Order Mark (BOM), I remove the NewDataSet, and I import the resulting XSD in MEC Mapper.
Here is the output in MEC Mapper:
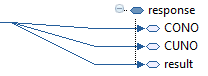
The result will be XML.
XSL Transform
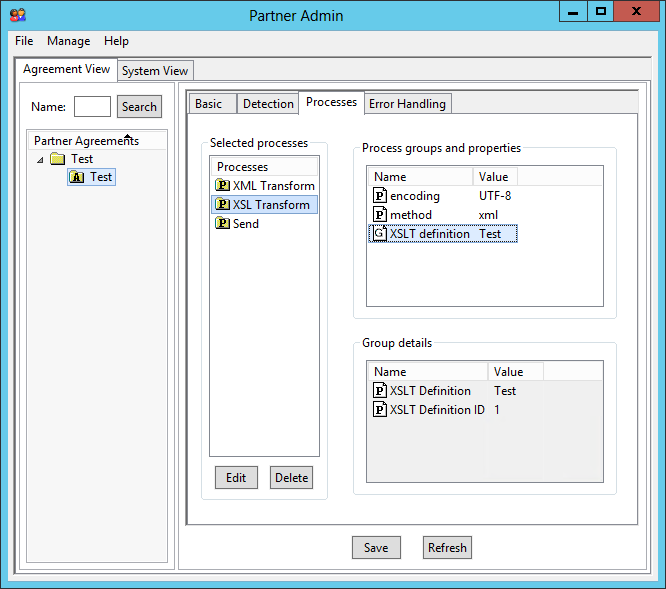
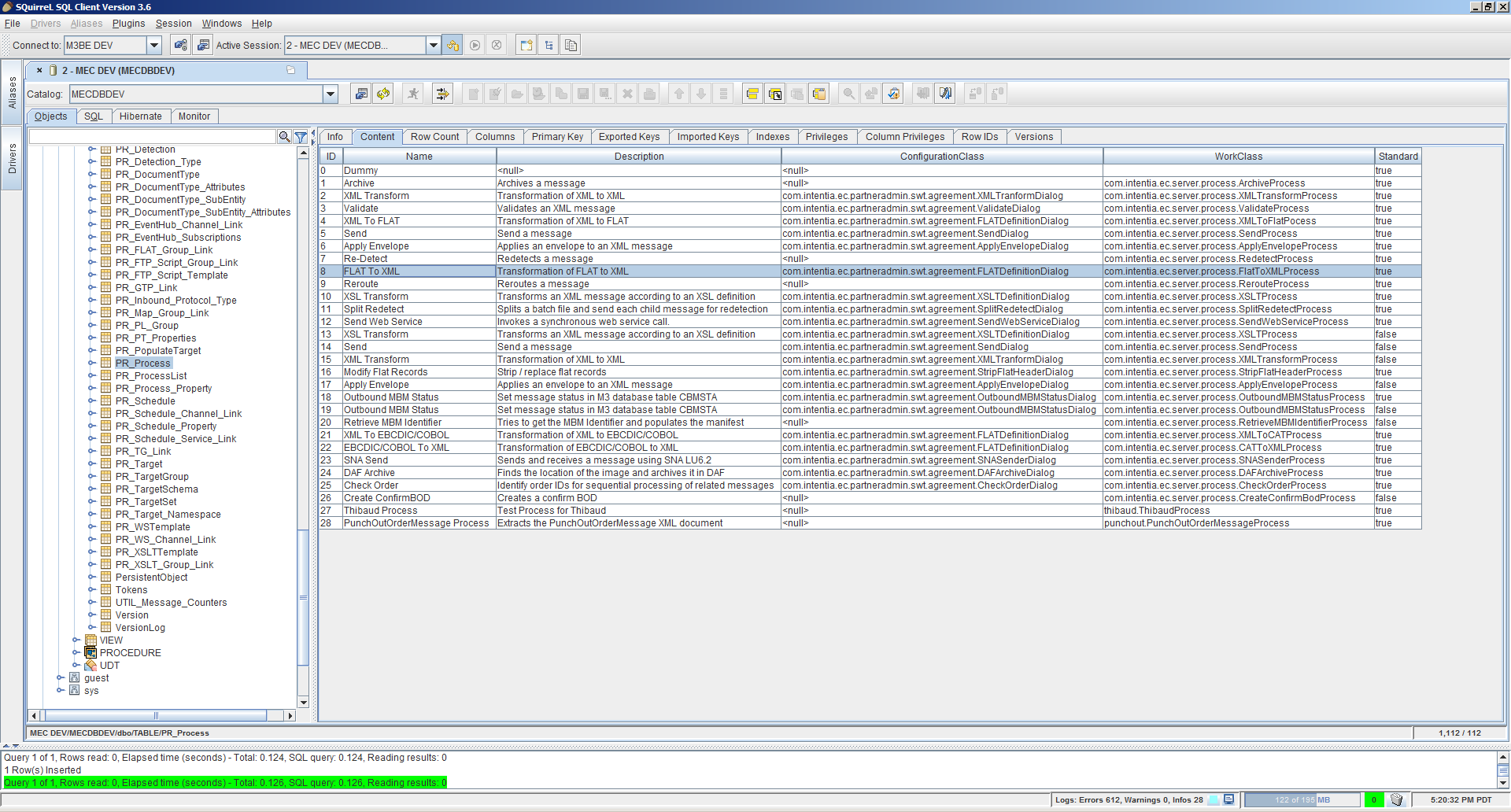
I will use XSL Transformations (XSLT) to transform the XML into HTML. For that, create the XSLT file with your favorite editor, go to Partner Admin > Manage, and add an XSLT Definition:

Then go to your agreement > Processes, add an XSL Transform process between XML Transform and Send, and set it to the XSLT Definition:

Here is a subset of my XSLT (the complete version includes the rest of the HTML):
<?xml version="1.0"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" doctype-system="about:legacy-compat" encoding="UTF-8" indent="yes" omit-xml-declaration="yes" />
<xsl:template match="/response">
<html>
<body>
Company: <xsl:value-of select="CONO" />
Customer: <xsl:value-of select="CUNO" />
<xsl:choose>
<xsl:when test="result='OK'">Customer added successfully to M3.</xsl:when>
<xsl:otherwise>Error: <xsl:value-of select="result" /></xsl:otherwise>
</xsl:choose>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
The result will be HTML.
Note 1: I use a choose-when-otherwise to display the success and error message differently.
Note 2: I set the xsl:output properties like doctype and omit-xml-declaration in the XSLT file itself, because if I set them in the XSL Transform process properties in Partner Admin then there is no or an incorrect effect (MEC bug?).
Send
Set the Send process in the agreement to Content-type text/html:

Static files
As per the basic rules of web pages, I will make the CSS and JavaScript external, with the CSS at the top and scripts at the bottom.
We can put the static files (images, CSS, JavaScript) on any web server of our choice. I did not find a generic web server in MEC, so for now I put the files in the M3 UI Adapter (MUA) folder at \\host1623\D:\Infor\LifeCycle\?\grid\?\grids\?\applications\M3_UI_Adapter\webapps\mne\, and the files are now accessible at http꞉//host1623:22107/mne/ (I will move them to a sub-folder later):

Note: I had originally put the files in the Smart Office MangoServer webapp that serves the ISO Installation Point (IP) at \\host1762\D:\Infor\LifeCycle\?\grid\?\grids\?\applications\MangoServer\Client\IP\ but the server returned the JavaScript as an attachment, and the browser downloaded the JavaScript file instead of executing it. So I moved them to the mne folder which returns the correct content type.
Incorrect:
Content-Disposition: attachment; filename=Test.js
Content-Type: application/x-download
Correct:
Content-Type: application/x-javascript |
Then, set the URLs accordingly in the HTML:
<link href="http://host1623:22107/mne/Test.css".../>
<img src="http://host1623:22107/mne/Test.png".../>
<script src="http://host1623:22107/mne/Test.js".../>
Result
You can now test the result. MEC will produce XML and will use XSLT to transform the XML into HTML, the browser will get the HTML and will follow the links to get the static files and render the result, and the user will see a nice HTML page that it can interact with.
Here is the result for one of my customers, and it is coming straight from MEC; users love it, they can click on the links to open the records in Smart Office, they can print it, save it as PDF, etc.:
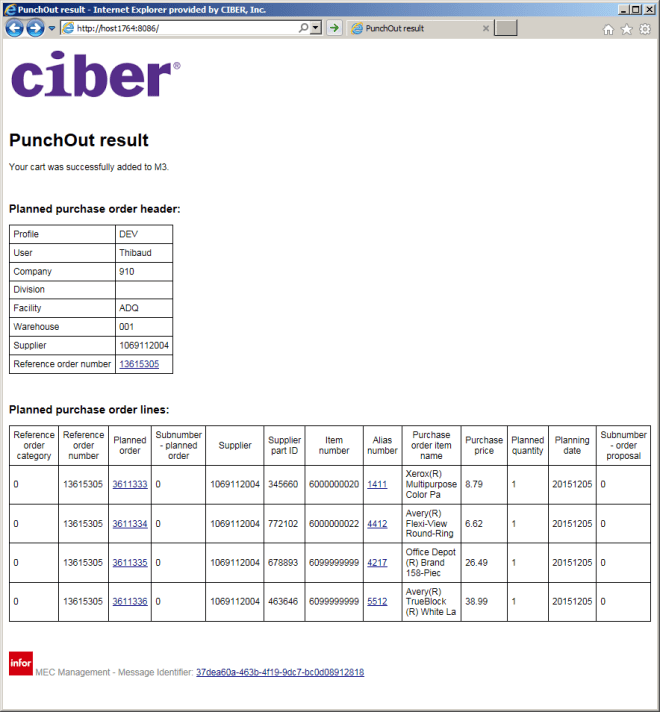
What about you
If you have an existing MEC mapping/agreement that produces XML, and you want to get this HTML solution:
- Create the static files (images, CSS, JavaScript) and place them somewhere in a web server
- Create the XSLT file that transforms the XML into HTML, set the URL of the static files accordingly, and add the XSLT to the Partner Admin > XSLT Definitions
- Add an XSL Transform process to your agreement (between XML Transform and Send), and set the Send content type to text/html
There is nothing to change in the MEC mapping. There is no server to reload.
Maintenance
With this design we have separation of concerns between data, presentation, and control, and it is easier to maintain than my original idea to do HTML output from the mapping:
- XML: maintain the XML as usual in MEC Mapper
- Static files (images, CSS, JavaScript): update the files with your favorite editors, and save them directly to the file system
- XSLT/HTML: update the file with your favorite editor, save directly to the file system, and update the XSLT Definition
- XSLT Definition: in the Partner Admin, delete the XSL Transform from the agreement and save it, select the new XSLT file in the XSLT Definition, re-add the XSL Transform to the agreement and save
Each step can be maintained individually by the same developer or by separate developers.
Note: MEC is not collaborative for developers, so if two developers are working on the same agreement in MEC Partner Admin (e.g. one maintaining the XML Transform, the other maintaining the XSL Transform) then the agreement will be corrupted.
Future work
There is more work to be done:
- Move the static files to another web server (who knows what will happen to the mne folder with upgrades of M3)
- Select the environment dynamically for the Smart Office Installation Point (DEV, TST, PRD)
- Set the text to the local language (English, Swedish, French, etc.)
- Get the column headings (CONO, CUNO, etc.) from the M3 language constants using the M3 translate API [4] instead of hard-coding the values
- Implement the Post/Redirect/Get pattern to avoid duplicate form submission when users click the back button, and to not sanction users that save the page in the browser bookmarks
- For easy cross-reference to the MEC Management log files, output the manifest UUID to the XML output using the Java method com.intentia.ec.mapper.Mapping.getManifestInfo(“UUID”), and add a link to it in the HTML with the href to https://host1764:22108/grid/ui/#com.lawson.ec.gridui.page.MessageDetailPage/MECSRVDEV?uuid/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
- One time I received the error “Internet Explorer has modified this page to help prevent cross-site scripting” (it is related to the same origin policy of browsers), but I have not been able to reproduce it. Otherwise it is working fine with my URLs spread across three hosts. To be troubleshot.
Conclusion
That was my solution for MEC to give custom, rich, interactive, and user-friendly HTML responses to the users. This is useful where the user needs an immediate response. All you have to do is add the XSL Transform and the static files without touching the existing mapping. In most of the cases, the classic responses – canned response, XML, or email – are sufficient.
That’s it! Special thanks to my colleague Sheryll Limmex for the help with the MEC mapping.
What solution did you design? Let me know in the comments below.